Dharma OCR: specialization that outperforms the largest AI models
For AI models to work well, they need structured data. The challenge in enterprise AI adoption is that much of this data is locked in documents: PDFs, forms, invoices, contracts. Processing those documents into structured data requires OCR. But traditional OCRs fail with varied layouts and specialized vocabulary; and LLMs (large AI models) handle the problem well, but are expensive and unviable at scale.
The answer is a smaller model, trained specifically for a task, that outperforms large generalist models on that same task, and at lower cost.
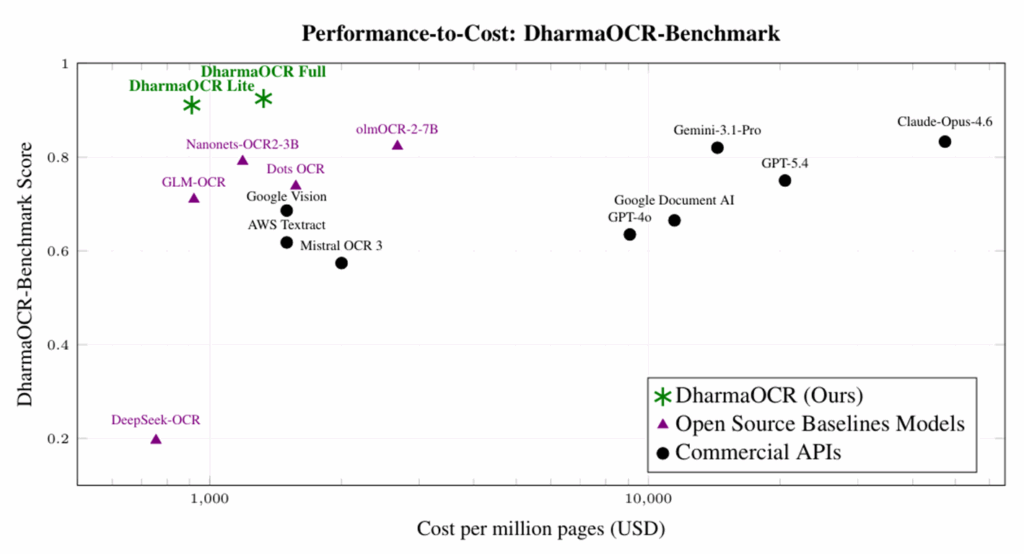
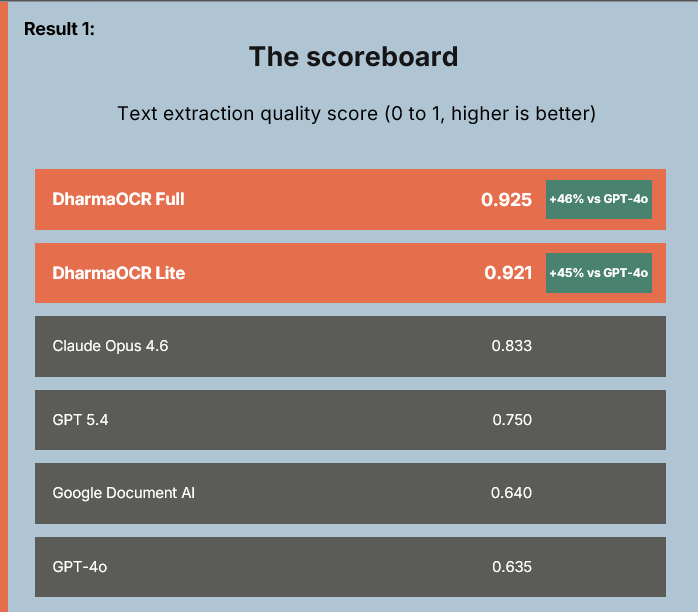
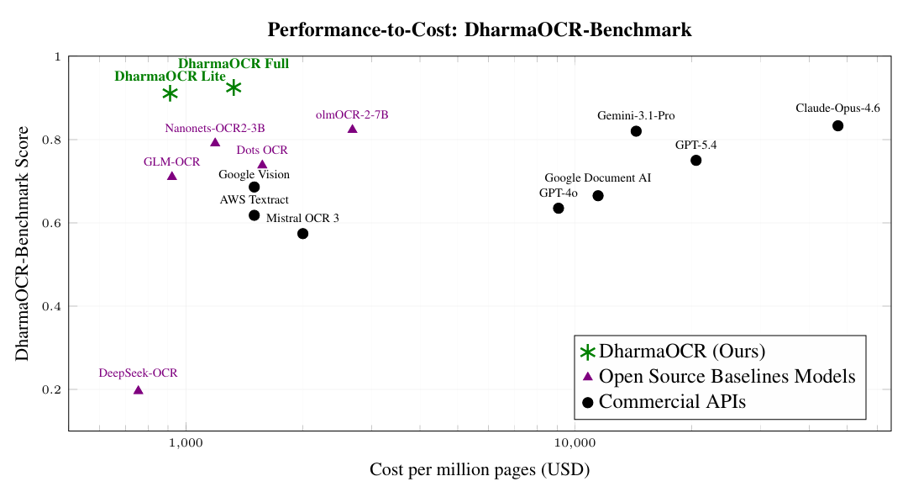
To prove this, we developed DharmaOCR-Benchmark and evaluated different model families across multiple sizes, combining SFT (Supervised Fine-Tuning) to enforce a strict JSON schema with DPO (Direct Preference Optimization) to explicitly penalize degenerate generations (when the model falls into repetitive patterns). The result was DharmaOCR Full (7B) and DharmaOCR Lite (3B), which achieved top scores of 0.925 and 0.921 on text extraction, outperforming GPT-4o, Google Document AI, and Claude Opus 4.6. With a degeneration rate of just 0.20% (versus up to 33.96% without specialization) and per-page cost reduced by up to 22% via AWQ quantization, the models dominate the quality-vs-cost frontier across all evaluated systems.
Specialization beats generalism on specific tasks. For document processing, this difference is measurable, significant, and economically relevant.
Models & datasets: https://huggingface.co/Dharma-AI
Full paper: https://arxiv.org/abs/2604.14314
Paper summary: https://gist.science/paper/2604.14314