Dharma OCR: especialização que supera os maiores modelos de IA
Para que modelos de inteligência artificial funcionem bem, eles precisam de dados estruturados. O problema no uso empresarial de I.A. é que grande parte desses dados está presa em documentos: PDFs, formulários, notas fiscais, contratos. Para processar os documentos e ter dados estruturados, é necessário OCR. Mas as OCRs tradicionais falham com layouts variados e vocabulário especializado; e LLMs (modelos grandes de I.A) encaram bem o problema, mas são caros e inviáveis em escala.
A resposta é um modelo menor, treinado especificamente para uma tarefa, que supera modelos generalistas de grande porte nessa mesma tarefa, e com menor custo.
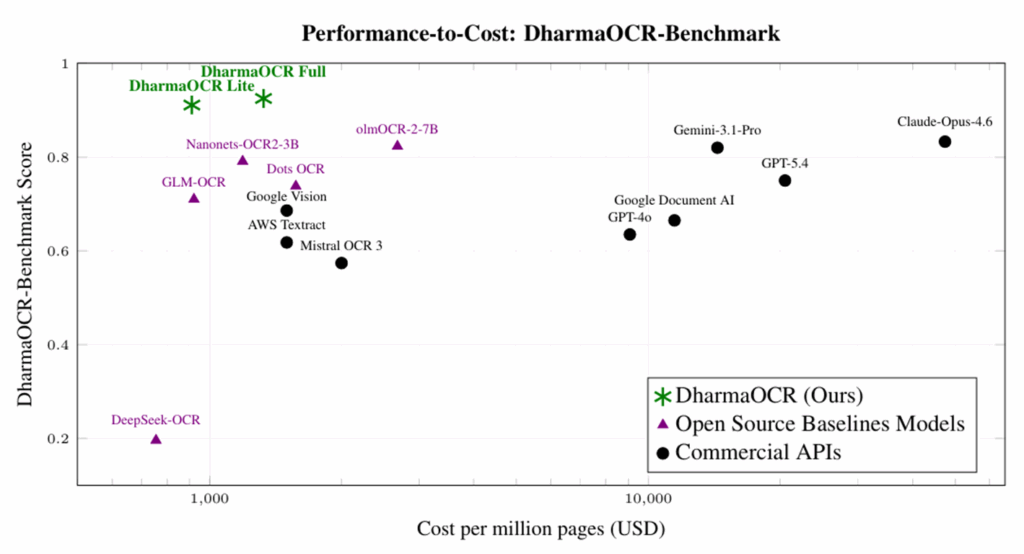
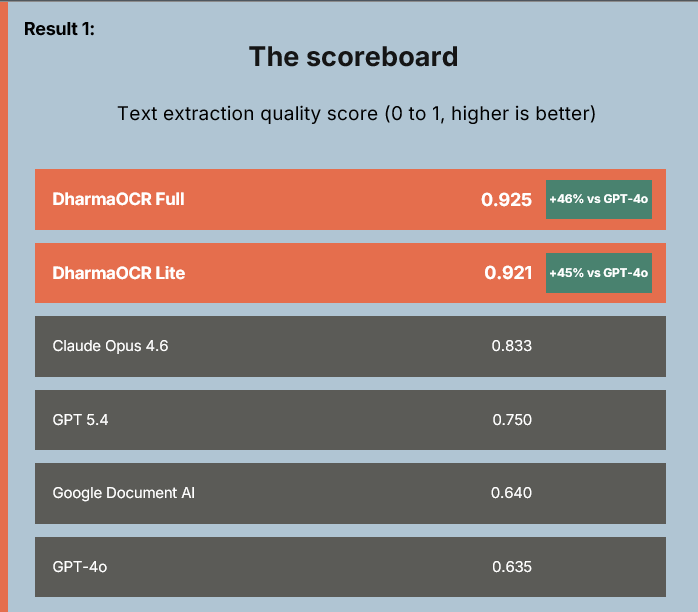
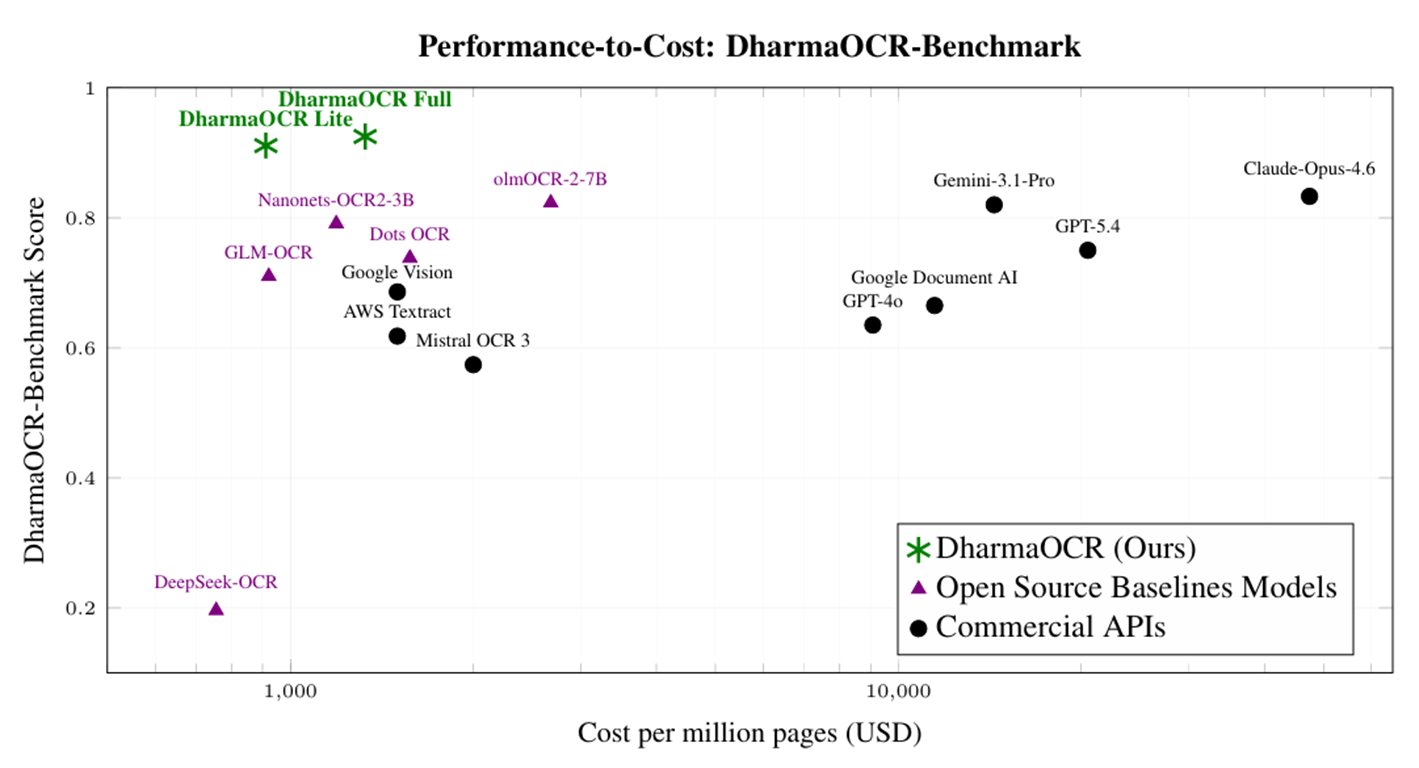
Para comprovar isso, desenvolvemos o DharmaOCR-Benchmark e avaliamos diferentes famílias de modelos em múltiplos tamanhos, combinando SFT (supervised fine-tuning) para impor um schema JSON rígido com DPO (Direct Preference Optimization) para penalizar explicitamente gerações degeneradas (quando o modelo entra em padrões repetitivos). O resultado foram o DharmaOCR Full (7B) e o DharmaOCR Lite (3B), que atingiram scores de 0,925 e 0,921 na extração de texto, superando GPT-4o, Google Document AI e Claude Opus 4.6. Com taxa de degeneração de apenas 0,20% (até 33,96% sem especialização) e custo por página reduzido em até 22% via quantização AWQ, os modelos dominam a fronteira de qualidade vs. custo entre todos os sistemas avaliados.
Especialização vence generalismo em tarefas específicas. Para processamento de documentos, essa diferença é mensurável, significativa e economicamente relevante.
Modelos e datasets: https://huggingface.co/Dharma-AI
Paper completo: https://arxiv.org/abs/2604.14314
Resumo do paper: https://gist.science/paper/2604.14314